返回首页
返回首页

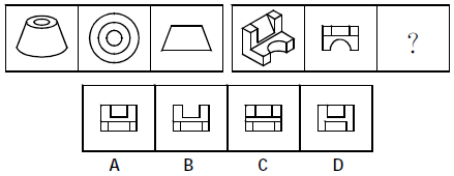
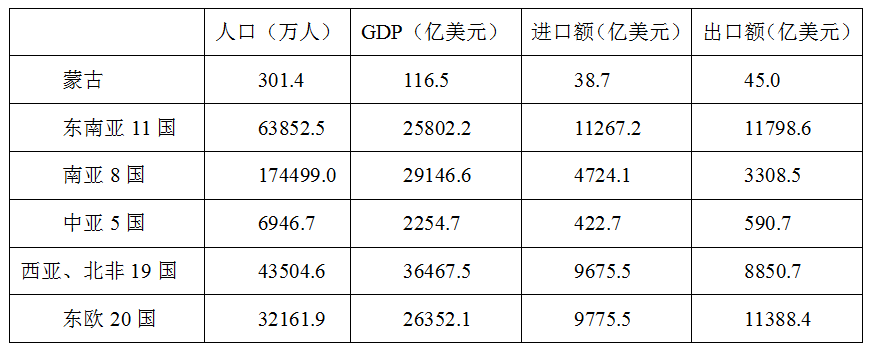
计算机考研:数据结构常用算法精析(9)
 查字典公务员网
查字典公务员网
第十章
内部排序(在内存中进行的排序不需要访问外存的)外部排序(排序量很大,通过分批的读写外存,最终完成排序)
稳定排序和非稳定排序:看相同记录的相对次序是否回发生改变。主要看在排序过程中的比较是不是相邻记录,如果是相邻比较,一定是稳定的排序。如果不是相邻的比较,就是不稳定的。
内排序方法 截止目前,各种内排序方法可归纳为以下五类:
(1)插入排序;(2)交换排序;(3)选择排序;(4)归并排序; (5)基数排序。
插入排序:包括直接插入排序和希尔排序
直接插入排序:(稳定的)
算法描述
void Insort (sqList L) ∥对顺序文件F直接插入排序的算法∥
{ int i,j;
for (i=2;ii++) ∥插入n-1个记录∥
{
if(L.R[i].key
{ L.R[0]=L.R[i]; ∥待插入记录先存于监视哨∥
L.R[i]=L.R[i-1];
for(j=i-2;L.R[0].key
L.R[j+1]=L.R[j]; ∥记录顺序后移∥
L.R[j+1]=L.R[0]; ∥原R[i]插入j+1位置∥
}
}
}
算法分析
设排序中key比较次数为C,C最小时记为Cmin,最大时记为Cmax。
(1)当原来就有序(正序)时,每插入一个R[i]只需比较key一次,即:
(2)当原本逆序(key从大到小)时,每插入一个R[i]要和子表中i-1个key比较,加上同自身R[0]的比较,此时比较次数最多,即:
(3)记录总的移动次数m(m最小时记为mmin,最大时记为mmax)
正序时,子表中记录的移动免去,即:
逆序时,插入R[i]牵涉移动整个子表。移动次数为2+(i-1)=i+1,此时表的移动次数最大,即:
排序的时间复杂度取耗时最高的量级,故直接插入排序的T(n)=O(n2)。
Shell(希尔)排序又称缩小增量排序(不稳定的)
交换类的排序:(起泡排序和快速排序)
起泡排序算法描述
void Bubsort (sqList L)
{ int i,flag; ∥flag为记录交换的标记∥
Retype temp;
for (i=L.len;ii--) ∥最多n-1趟排序∥
{ flag=0; //记录每一趟是否发生了交换
for (j=1;jj++) ∥一趟的起泡排序∥
if (L.R[j].keyL.R[j+1].key) ∥两两比较∥
{ temp=L.R[j]; ∥R[j] R[j+1]∥
L.R[j]=L.R[j+1];
L.R[j+1]=temp;
flag=1;
}
if (flag==0) break; ∥无记录交换时排序完毕∥
}
}
算法分析
设待排长度为n,算法中总的key比较次数为C。若正序,第一趟就无记录交换,退出循环,Cmin=n-1=O(n);若逆序,则需n-1趟排序,每趟key的比较次数为i-1(2n),故:
同理,记录的最大移动次数为:
故起泡排序的时间复杂度T(n)=O(n2)。并且是稳定的。
快速排序:(不稳定的,时间复杂度O(nlogn)),不需要辅助空间,但有最好和最差之分
分割算法
int Partition(SqlistL,int low,int high)
{ L.R[0]=L.R[low];
pivotkey=L.R[low].key;
while(low
{ while(low=pivotkey)
--high;
L.R[low]=L.R[high];
while(low
++low;
L.R[high]= L.R[low];
}
return low;
}
总控函数:
void QSort(SqlistL,int low,int high)
{ if(low
{
pivotloc=Partition(L,low,high);
QSort(L,low,pivotloc-1);
QSort(L,pivotloc+1,high);
}
}
调用方法:QSort(L,1,L,lenght);
算法分析:
若原本就正序或逆序,每次调用一次后,记录数只减少了一个,故此时T(n)=C(n+(n-1)++1)=O(n2)。这是快速排序效率最差的情况。所以快速排序算法有待改进。
简单选择排序: 属于稳定排序时间复杂度(O(n2))
算法描述
void Slectsort (Sqlist L) ∥直接选择排序的算法∥
{
for (i=1;i
{
j=SeloctMinkey(L,i); //从i到L.len中选择key最小的记录
if (i!=j)
{ temp=L.R[i];
L.R[i]=L.R[j];
L.R[j]=temp;
}
}
}
堆排序:属于选择排序 不稳定,时间复杂度(O(nlogn)),没有最好和最差的分别,也需 要辅助的栈空间
若kik2i、kik2i+1。此时,根结点k1的值最大,称为大根堆。
若kik2i、kik2i+1满足关系,则k1最小,称为小根堆。
在堆排序中,我们采用的是大根堆,原因是大根堆中,根最大,对删除很方便,直接把它与最后一个叶子结点交换就可以了。
记录key集合k={k1 k2kn}, 排序 分两步进行:
(1)将{k1 k2kn}建成一个大根堆;
(2)取堆的根(key最大者),然后将剩余的(n-1)个key又调整为堆,再取当前堆
的根(key次大者),,直到所有key选择完毕。
一个元素的堆调整算法:
//已知H.R[s...m]除H.R[s]之外,均满足堆的定义,本函数只是将H.R[s]放到已经是堆的堆中
void HeapAdjust (SqList H, int s, int m) ∥将(H.R[s]H.R[m])调整成大根堆∥
{
rc=H.R[s]; ∥暂存H.R[s]∥
for(j=2*s;j j*=2 )//沿key较大的孩子结点向下筛选
{
if (jL.R[j].key) j++; ∥令j为s的左右孩子key最大者的序号
if (rc.keyL.R[j].key)
break;//说明H.R[s]已经比当前堆中的所有元素大,已经是堆了,不需要调整了
L.R[s]=L.R[j]; ∥把最大的放到根结点
s=j; ∥把s与j交换,使得s与下层的堆比较
}
L.R[s]=rc; ∥最初的根回归∥
}
void Heapsort (SqList H) ∥ 堆排序算法∥
{
//初始建堆
for (i=L.len/2; i i--) //从完全二叉树的最后一个非叶子结点开始
HeapAdjust (L,i,L.len); ∥调整(R[i]R[n])为堆∥
//每次取下根(最大的元素)所谓的取下,只是放到数组最后,改变一下数组的下界
for (i=L.len;ii--) ∥总共摘n-1次∥
{ temp=F.R[1]; ∥根与当前最后一个结点互换∥
F.R[1]=F.R[i];
F.R[i]=temp;
HeapAdjust (L ,1,i-1); ∥把最后一个元素调整到合适的位置∥
}
}
二路归并排序:(稳定的,时间复杂度O(nlogn)又稳定又效率高,但需要辅助空间TR[1....n]
二路归并得核心操作是将一维数组中前后相邻的两个有序序列归并为一个有序序列
(注意这就是线型表中我们常考的那个,两个有序链表合成一个新的有序表)
算法描述如下:
void Merge(RcdType SR[],RcdTypeTR[],int i,int m,int n)
//将有序的SR[i...m]和SR[m+1....n]归并为有序的TR[i....n]
{
for(j=m+1,k=i; i=n; ++k) //谁小就先将谁放进TR
{ if(SR[i].key=SR[j].key)
TR[k]=SR[i++];
else
TR[k]=SR[j++];
}
if(i=m) //将剩余的SR 直接放到TR
TR[k....n]=SR[i...m];
if(j=n) //将剩余的SR 直接放到TR
TR[k...n]=SR[j....n];
}
void MSort(RcdType SR[], RcdTypeTR1[], int s, int t)
{ //将SR[s...t]归并排序为TR1[s...t]
if(s= =t) //只有一个元素
TR1[s]=SR[s];
else
{
m=(s+t)/2;//将SR[]平分为两半
MSort(SR, TR2, s, m);
MSort(SR, TR2, m+1, t);
Merge(TR2, TR1, s, m, t);
}
}